
Concepts:
This post demonstrates systematic approaches to solve DP problem. First, a brute force solution is discussed. Then 2 DP approaches, Top-Down and Bottom-Up are used to solve the problem. We also analyze the problem by identifying the state, state variables, base cases, and recurrence relations.
Sample problem Longest Common Subsequence:
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
For example, "ace" is a subsequence of "abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:
Input: text1 = "abcde", text2 = "ace"
Output: 3 Explanation: The longest common subsequence is "ace" and its length is 3.
Example 2:
Input: text1 = "abc", text2 = "abc"
Output: 3Explanation: The longest common subsequence is "abc" and its length is 3.
Example 3:
Input: text1 = "abc", text2 = "def"
Output: 0Explanation: There is no such common subsequence, so the result is 0.
Constraints:
1 <= text1.length, text2.length <= 1000
text1 and text2 consist of only lowercase English characters.Solution 1: Brute Force
Problem analysis:
- repeated character may appear in any text. For example:
text1 = abcaeandtext2 = cae,caeis the common subsequence, butaceis not. - consequently, if a character matches another character in the 2nd text, it must be in order.
- iterate through each subsequence of the first string and check whether or not it is also a subsequence of the second string. (the characters in 2nd string could be put in a hashmap with key-value). The value would indicate the order in which the characters appear in the 2nd string.
- This will require exponential time to run. The number of subsequences in a string is up to 2^L , where L is the length of the string. This is because, for each character, we have two choices; it can either be in the subsequence or not in it. Duplicates characters reduce the number of unique subsequences a bit, although in the general case, it's still exponential.
Solution 2: Top-down + memoization
Approach:
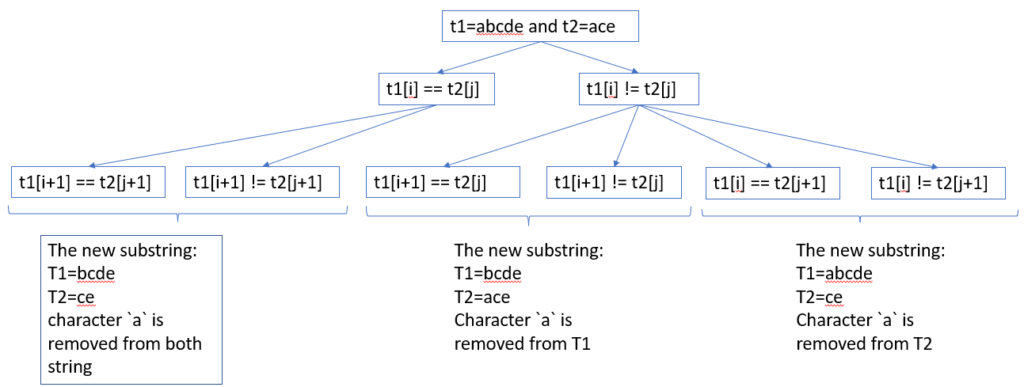
- consider a decision tree where each node is pair of substrings from
text1andtext2. The first character of the substrings are compared, and could be used or wont be used in the child node. - In order word, each state compares the 2 first characters of substrings from
text1, andtext2. - If the characters match, the characters are removed from both original strings.
- If the characters dont match, the character is kept from either string, and compared to the next character of the other string.
- We now can defines the basic terms for DP solution:
- state: each state compares the first characters of the
substringsofText1,Text2 - state variable:
iis index of first character in substringText1;jis index of first character in substring oftext2. - recurrence relation: For top-down solution, we define recursive call
compareNext, where:- if characters match,
answer = 1 + compareNext(i+1,j+1) - in the next state, we removed the characters from both string and compare the next characters of both string. Thus we compare
Text1[i+1]andText2[j+1] - if characters dont match,
answer = max(compareNext(i+1,j), compare(i,j+1) - we removed a character from either string, and keep the other. The character is then compared to the next charact of the other string.. Thus we compare between
Text1[i+1]andText2[j]orText1[i]andText2[j+1].
- if characters match,
base case:
- return 0 when
iorjis out-of-bound.i == text1.length()orj == text2.length(). It is because no more character on either string is available for comparison.
- return 0 when
i and j are changed in next state. Code
class Solution {
private:
vector<vector<int>> cache;
int compareNext(string & text1, string & text2, int i, int j){
// memoization:
if (cache[i][j] != -1) {
return cache[i][j];
}
// base case:
if (i == text1.length() || j == text2.length()){
return cache[i][j] = 0;
}
// recurrence case:
if (text1[i] == text2[j]){
cache[i][j] = 1 + compareNext(text1, text2, i+1, j+1);
}
else{
cache[i][j] = max (compareNext(text1, text2, i+1, j), compareNext(text1, text2, i, j+1));
}
return cache[i][j];
}
public:
int longestCommonSubsequence(string text1, string text2) {
cache.resize(text1.length()+1, vector<int> (text2.length()+1,-1));
return compareNext(text1, text2, 0 , 0);
}
};Complexity Analysis
- Time Complexity:
- Space Complexity:
Solution 3: Bottom-up
Code
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int>> DP (text1.length()+1, vector<int> (text2.length()+1,0));
for (int i = text1.length()-1; i>=0; i--){
for (int j = text2.length()-1; j>=0; j--){
// cout<<i<<" "<<j<<endl;
if (text1[i] == text2[j])
DP[i][j] = 1 + DP[i+1][j+1];
else
DP[i][j] = max(DP[i+1][j], DP[i][j+1]);
}
}
return DP[0][0];
}
};