
Introduction
I continue to analyze how to construct 1D matrix and use iteration technique from a decision. In this blog, I attempt to focus on how each cell in 2D or 1D matrix should match with the nodes in a decision tree. Thus if we can intuitively come up with a good decision tree, we can implement iteration technique, which I think provides easier way to debug, and is also more efficient.
Not every decision tree are equal. For some problems, we could re-analyse the state variables and values to come up with cleaner relation.
In this blog, I solve problems with recursive solutions. But for iterative solutions, I have to "rethink" simpler decision tree.
Problem Number of Dice Rolls With Target Sum
I will attempt the problem Number of Dice Rolls With Target Sum with a recursive solution that solves only 40/60 test cases.
Then I will reconstruct a different decision tree and implement with recursive solution (Top down), and iteration solution (Bottom up) using 2D DP array.
Finally I represent a best optimized solution using 1D DP array and Prefix sum technique.
Recursive
First I com up with the following decision tree:
- each level has the output rolling a dice. We have
ndices, thusnlevel. - each parent node has
kpossible outcomes, because each roll can result in any face. We havekfaces, thus each parent node has the samekbranches. - base case happen at leaf nodes:
- either all dices have been rolled, and the
sumis still not the target, return zero or thesumis greater than the target before all dices have been rolled. - all dice have been rolled and the sum is same as the target, return 1, as we found away.
- either all dices have been rolled, and the
- Since each node is represented by the
diceIndexand thefaceIndex, I use 2D array as memoization.
Using the above trees, I have the following code implementation:
class Solution {
const int MOD = 10000000;
int roll(int& n, int& k, int& target, int diceIndex, int currFaceIndex, int sum, vector<vector<int>>& memo ){
// base case:
if (diceIndex == n && sum == target)
return 1;
if (diceIndex >= n || sum > target)
return 0;
// memoization:
if (memo[diceIndex][currFaceIndex] !=-1)
return memo[diceIndex][currFaceIndex];
// relation:
int count =0;
for( int faceIndex =1 ; faceIndex <= k; faceIndex++){
count += roll(n,k, target, diceIndex+1, faceIndex, sum+faceIndex, memo) % MOD;
}
return memo[diceIndex][currFaceIndex] = count;
}
public:
int numRollsToTarget(int n, int k, int target) {
vector<vector<int>> memo (n+1, vector<int>(k+1, -1));
return roll(n,k,target, 1, 1, 0, memo );
}
};The above solution fixes only 40/60 test cases !!! The error is (to be added)
Rethink the decision tree
Now I decide the change the state variables:
- each node is represented by the diceIndex and accumulated sum (
currSum)- we still have n levels for we have n dices.
- accumulated sum is calculated as previous node sum added with the face value.
- the return value of each node is the count of possible ways.
- base conditions are still same as above approach:
- if
diceIndex == nandcurrSum = target.
- if
Note the following logic are the same:
// base case:
if (sum == target && diceIndex == n)
return 1;
else return 0;
// same as:
if ( diceIndex == n)
return sum == target;
// same as:
if (diceIndex == n && sum == target)
return 1;
if (diceIndex >= n || sum > target)
return 0;The following illustrates the decision tree:

Iteration with 2DP array.
From above analysis we can see that
- each node is represented by 2 state variables
diceIndexandcurrSum - each node stores the value of count, or how many ways to reach target
sum.
Therefore we could construct 2D arrays to represent the same nodes.
Instead of using recursive call, we could use simple formula to update the cells:
parent cell = dp[diceIndex][currSum]child cell = dp[diceIndex-1][currSum - currFaceIndex]=parent cell + 0 if parent cell is 1 or dp[0][0]=1
Pay attention to the subtractions! With the above formular, the currSum will get progressively larger at the child nodes, the count values also get larger and larger!!! I will get the result at the rightmost bottom leaf nodes or dp[n][target]!!!
To map the value of DP array with decision tree node, I use test case n=2, k=3 and target=6. The following illustrate how each dp cell matches with the tree node.
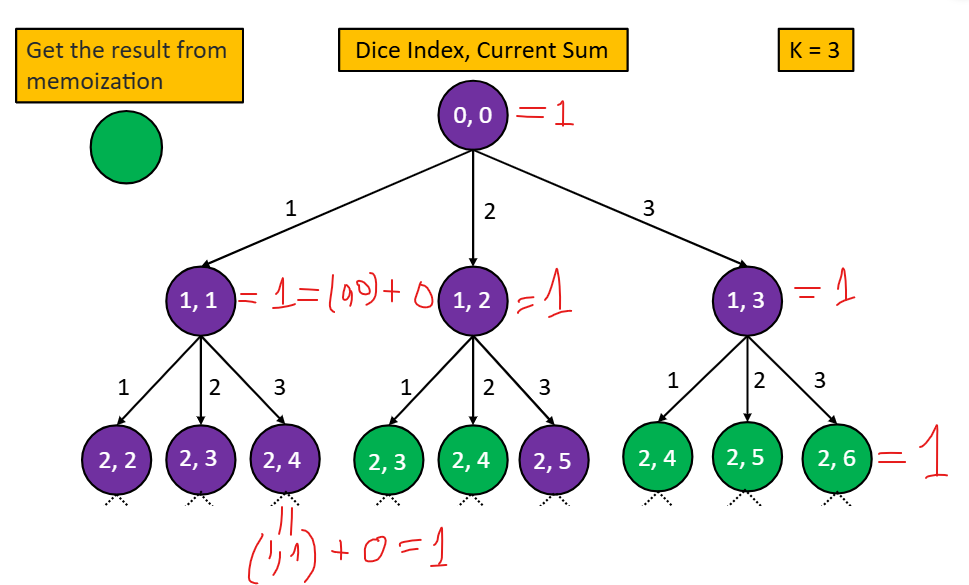
class Solution {
public:
const int MOD = 1e9 + 7;
int numRollsToTarget(int n, int k, int target) {
vector<vector<int>> dp(n + 1, vector<int>(target + 1, 0));
// Initialize the base case
dp[0][0] = 1;
for (int diceIndex = 1; diceIndex <= n; diceIndex++) {
for (int currSum = 0; currSum <= target; currSum++) {
int ways = 0;
// Iterate over the possible face value for current dice
for (int i = 1; i <= k; i++) {
if (currSum - i >= 0) {
ways = (ways + dp[diceIndex - 1][currSum - i]) % MOD;
}
}
dp[diceIndex][currSum] = ways;
}
}
return dp[n][target];
}
};Notes: It is especially tricky but vital construct correct values for:
- the root node or
dp[0][0] - how each node or
dp[diceIndex][currSum]cell should be updated, and if the child nodes should be calculated from the parent nodes - which cell gives the final answer. Is it dp[n][target] or dp[0][0]
Iteration - 1D DP array
Instead of using 2D arrays, we could use two 1D arrays.
- observe that each row in 2D arrays corresponds to a level in the decision tree
- each child row have its cells updated and calculated by cells in higher/previous rows.
Therefore, why not just use two 1D arrays:
- a newDp array to calculate the cells of each rows.
- a Dp array to store the cells value of the previous row. Because cell is calculated by sum.
#include <vector>
#include <algorithm>
class Solution {
public:
int numRollsToTarget(int n, int k, int target) {
const int MOD = 1000000007;
// Initialize an array to store the number of ways to achieve each sum
std::vector<int> dp(target + 1, 0);
dp[0] = 1;
// Iterate over the number of dice
for (int i = 1; i <= n; i++) {
// Create a new array to store the updated number of ways for the current dice count
std::vector<int> newDp(target + 1, 0);
int sum = 0; // Variable to calculate the prefix sum
// Iterate over possible sums
for (int j = 1; j <= target; j++) {
// Calculate the number of ways to achieve the current sum using 'i' dice
// Update sum with the current element from the previous row
sum = (sum + dp[j - 1]) % MOD;
// If the current sum is greater than k, subtract the contribution from k+1 steps back
if (j >= k + 1) {
sum = (sum - dp[j - k - 1] + MOD) % MOD;
}
// Update the newDp array with the calculated sum
newDp[j] = sum;
}
// Update dp array with the newDp array for the next iteration
std::copy(newDp.begin(), newDp.end(), dp.begin());
}
return dp[target];
}
};Problem Paint Fence
This problem is very similar to the problem Paint House. With that problem it is very intuitive to construct a 2D array to calculate the cost of painting houses. After we reiterate down the row (based on the number of houses), and over the columns (based on the number of color), we can update each cells (cost of painting based on the values in previous row. That problem is also similar to problem Calculating Min Path in a Grid or Min Falling Path in a grid.
But for this problem, it is not possible to construct 2D grids using the same approach. I start here with a recursive solution and derive a bottom up, iteration solution with 1D array.
Recursive solution (Top down)
Recursive solution attempts to construct a decision tree. The function colorFence is defined to calculate the number of ways to paint the fence starting from a given fenceIndex with a specific colorIndex and a count of consecutive same colors (sameColor).
Image to be updated
- Base case: If
fenceIndexequalsn, it means all fences are painted, so it returns1 - Recursive case:
- For each fence, there are all k color choices, except when 2 previous fence are of the same color. Thus we reiterate from
color index = 0tocolor index = k. - To go to child node/next fence, we could use the same
color, but have to incrementsameColorcount. Thus we make recursive call
- For each fence, there are all k color choices, except when 2 previous fence are of the same color. Thus we reiterate from
ways += colorFence(fenceIndex + 1, color, n, k, sameColor + 1, cache)- However, for case that 2 previous fences are of the same color, we still have to paint the next fence (move to next child node) but reset
sameColorto 1. The next next is painted with what ever color on the current loop.
ways += colorFence(fenceIndex + 1, color, n, k, 1, cache); // Reset sameColor to 1- Memoization needs 3D array! After much trial and error, I figured that it is required.
Code Implementation:
class Solution {
int colorFence(int fenceIndex, int colorIndex, const int &n, const int &k, int sameColor, vector<vector<vector<int>>>& cache) {
// base case
if (fenceIndex == n) { // Changed from n-1 to n
return 1; // Ensuring valid configurations return 1
}
// check memoization
if (cache[fenceIndex][colorIndex][sameColor] != -1) { // Changed from 0 to -1
return cache[fenceIndex][colorIndex][sameColor]; // Updated to use 3D cache
}
int ways = 0;
for (int color = 0; color < k; color++) {
if (color == colorIndex) {
if (sameColor + 1 < 3) { // Ensuring no more than two consecutive same colors
ways += colorFence(fenceIndex + 1, color, n, k, sameColor + 1, cache); // Updated recursive call
}
} else {
ways += colorFence(fenceIndex + 1, color, n, k, 1, cache); // Reset sameColor to 1
}
}
return cache[fenceIndex][colorIndex][sameColor] = ways; // Updated to use 3D cache
}
public:
int numWays(int n, int k) {
vector<vector<vector<int>>> cache(n, vector<vector<int>>(k, vector<int>(3, -1))); // Changed cache initialization
int ways = 0;
for (int color = 0; color < k; color++) {
ways += colorFence(1, color, n, k, 1, cache); // Start from fenceIndex 1
}
return ways;
}
};The above solution is very cumbersome.
Rethink the math:
Earlier, our approach has been based on the choices that we have at each fence. Thus each node/state, we have the fenceIndex, and colorIndex. The value of each node is derived from the child node plus 1.
If we have n fence and k colors, without constrain, the total way is n*k.
- Use a different color than the previous post. If we use a different color, then there are
k - 1colors for us to use. This means there are(k - 1) * totalWays(i - 1)ways to paint the ith post a different color than the (i−1)th post. - Use the same color as the previous post. There is only one color for us to use, so there are
1 * totalWays(i - 1)ways to paint the ith post the same color as the (i−1)th post. - Because of the constrain that no more than 2 adjacent fence can be painted the same color, there are
(k - 1) * totalWays(i - 2)ways to paint the the ith post a different color than the (i−2)th post. - Overally, we have
totalWays(i) = (k - 1) * (totalWays(i - 1) + totalWays(i - 2))
Iteration
From the above analysis, we could make a dp array, and update each cell of the array during iteration, using the formular dp[i] = (dp[i-1] + dp[i-2]) * (k-1)
class Solution {
public:
int numWays(int n, int k) {
// edge cases
if (n == 0) return 0;
if (n == 1) return k;
if (n == 2) return k*k;
// base cases
int dp[n+1];
dp[0] = 0;
dp[1] = k;
dp[2] = k*k;
for (int i = 3; i <= n; i++) {
// the recursive formula that we derived
dp[i] = (dp[i-1] + dp[i-2]) * (k-1);
}
return dp[n];
}
};
// source: https://leetcode.com/problems/paint-fence/submissions/1373350360Problem Minimum Cost for Tickets
In order to construct 1D DP array for iteration technique, a very good decision tree should be made, because the cells in 1D DP array closely matches the nodes/states in decision tree.
As shown in early section, once we come up with a math formular to calculate state values, which also makes our decision tree cleaner, the relation between nodes simpler, we could easily come up with almost the same equation to calculate each cell in the 1D DP array.
In this problem, I come up with this decision tree at first.
- Each node represents the cost of tickets at each nums[i]. The state variable is the cost of tickets.
- Each node returns value which the cost of days[i].
image to be updated
But the decision tree is hard to implement because in other to go to each child node and return values, I have to check nums for the nums[i] = day using ticket. So why not use the days as the state variables? With that I have the following decision tree:
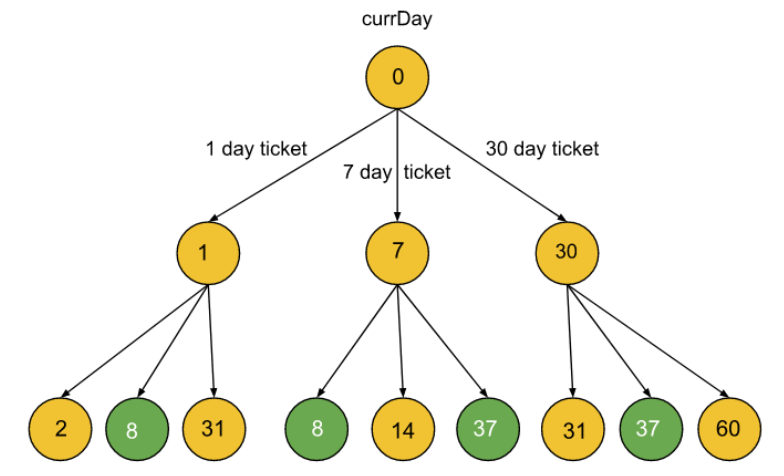
- each node state variable is the actual day. 1, ..... days[days.size() -1].
- each node return values, depending on the previous purchases.
- If the day is 5 for example, then the 7 days ticket has been bought, then the cost is just
7+0on the dp array:dp[7] = dp[5] + 0; - because we have 3 choices, thus on each day, the cost is the minim of the previous 3 scenarios:
- If the day is 5 for example, then the 7 days ticket has been bought, then the cost is just
dp[day] = Min(dp[day - 1] + costs[0], dp[day - 7] + costs[1], dp[day - 30] + costs[2];The relation equation is much simplier to implement in both recursive solution and iterative solution.
- The final cost is the
dp[lastDay]
Code implementation:
- initialize dp array whose size is the
last dayof days array.- all other values of days array doesn't matter in this problem. We only care about the last day.
- reiterate until
total day = lastDay. - If the current
dayis not a travel day (day < days[i]), the cost remains the same as the previous day (dp[day] = dp[day - 1]). - If the current
dayis a travel day (day == days[i]), the program calculates the minimum cost by considering three options:- Buying a 1-day ticket:
dp[day - 1] + costs[0] - Buying a 7-day ticket:
dp[max(0, day - 7)] + costs[1] - Buying a 30-day ticket:
dp[max(0, day - 30)] + costs[2] - Note that the
max(0, day - 7)andmax(0, day - 30)ensure that we do not access negative indices in thedparray.
- Buying a 1-day ticket:
class Solution {
public:
int mincostTickets(vector<int>& days, vector<int>& costs) {
int lastDay = days[days.size() - 1];
vector<int> dp(lastDay + 1, 0);
int i = 0;
for (int day = 1; day <= lastDay; day++) {
if (day < days[i]) {
dp[day] = dp[day - 1];
} else {
i++;
dp[day] = min({dp[day - 1] + costs[0],
dp[max(0, day - 7)] + costs[1],
dp[max(0, day - 30)] + costs[2]});
}
}
return dp[lastDay];
}
};Suppose we have inputs
days = [1, 4, 6, 7, 8, 20]costs = [2, 7, 15]
The dp array will be updated as follows:
dp[1] = min(2) = 2(1-day ticket)dp[2] = dp[1](no travel day)dp[3] = dp[2] = 2(no travel day)dp[4] = min(4 + 2, 0 + 7, 0 + 15) = 4(1-day ticket for each day)dp[6] = min(6 + 2, 0 + 7, 0 + 15) = 6(1-day ticket for each day)dp[7] = min(7 + 2, 0 + 7, 0 + 15) = 7(1-day ticket for each day)dp[9] = 7(no travel day)