
Introduction
In earlier blog, Thread and Process in C++ – My sky (freewindcode.com), I have explained some aspects of threads that are problematic:
- Threads can share and access same data, thus potentially give rise to Data Race issue.
- When a new thread is created from its main thread, CPU may run threads in any order. A program has no guarantees about which thread will next be scheduled to use the CPU or according to specified synchronization techniques.
In this blog, I explain concurrency. data race issue and the tools to implement thread synchronization.
Concept: Concurrency
Concurrency: running multithreads to perform tasks. The tasks however are switched between different threads.
- if the functions both impacted the same variable, sequential execution is preferred.
Parallelism: also running multithreads to perform tasks. However, the threads perform the same tasks together.

Concept: Race condition
Race condition describes the scenario that multiple threads can modify a value in uncontrollable, unexpected way, when no threads synchronization is implemented.
The following programs spawns 2 threads to increment the same global values in parallel.
- Each thread is started and runs a loop to increment the values.
- We have no control on which thread to run first .
- We have no control if a thread accesses the value at the same time or right after one another.
The result is that after each program run, the global value differs wildly.
#include <thread>
#include <iostream>
using namespace std;
static int glob = 0;
static void threadFunc(int loop)
{
for (int j = 0; j < loop; j++) {
glob++;
}
}
int main(int argc, char *argv[])
{
int loops=10000000;
std::thread t1 (threadFunc, loops);
std::thread t2 (threadFunc, loops);
t1.join();
t2.join();
std::cout<<glob<<endl;
return 0;
}Mutex
Mutex "lock" or "acquires" a part of codes, aka "critical section". We have:
- mutex object initialized in global scope.
- mutex locks at the beginning of the for loop and unlocks at the end of the
forloop. - thus, the threads run concurrently: thread t1 or t2 runs the entire
for loop. Then the remaining thread picks up theglobvalue and run the for loop.
Mutex performance
Mutexes are implemented using atomic machine-languageoperations (performed on memory locations visible to all threads) and require system calls only in case of lock contention.
Compared to using file lock in Linux to lock a critical section, mutex is faster.
The following program demonstrates the use of mutex.
#include <thread>
#include <iostream>
#include <mutex>
using namespace std;
static int glob = 0;
std::mutex mtx;
static void threadFunc(int loop)
{
mtx.lock();
const auto now = std::chrono::system_clock::now();
const std::time_t t_c = std::chrono::system_clock::to_time_t(now);
std::cout << "Time: " << std::ctime(&t_c);
std::cout<<"threadID: "<<std::this_thread::get_id()<<std::endl;
for (int j = 0; j < loop; j++) {
glob++;
}
mtx.unlock();
}
int main(int argc, char *argv[])
{
int loops=10000000;
std::thread t1 (threadFunc, loops);
std::thread t2 (threadFunc, loops);
t1.join();
t2.join();
std::cout<<glob<<endl;
return 0;
}After the program exit, the glob value is always 20000000, since each thread increments the glob value by 10000000
Time: Fri Aug 9 04:08:34 2024
threadID: 132559802152512
Time: Fri Aug 9 04:08:34 2024
threadID: 132559793759808
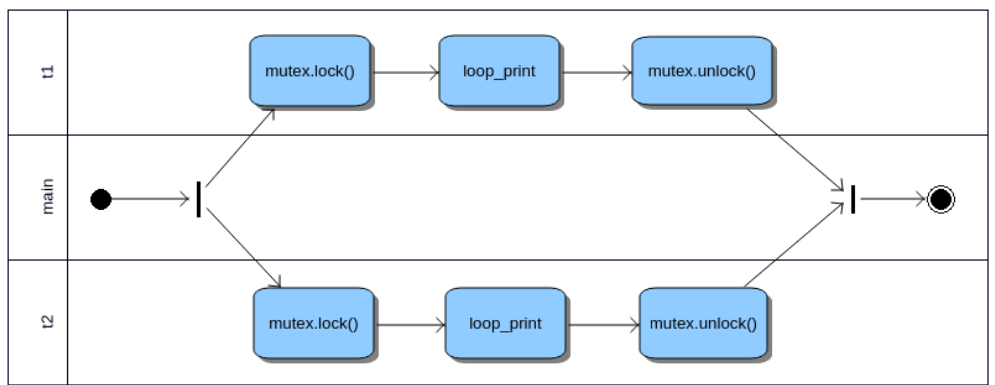
20000000Also notes that the thread start one after another, but we don't know which thread, t1 or t2, start first. The UML activity chart for the above program could be like this:
Lock_guard
The class lock_guard is a mutex wrapper that provides a convenient RAII-style mechanism for owning a mutex for the duration of a scoped block (Cplusplus Reference)
The following program demonstrates usage of lock_guard. In the program, lock_guard only locks the critical section within the braces {}, also the scope of function threadFunc.
#include <thread>
#include <iostream>
#include <mutex>
#include <chrono>
using namespace std;
static int glob = 0;
std::mutex mtx;
static void threadFunc(int loop)
{
std::lock_guard<std::mutex> lock(mtx);
const auto now = std::chrono::system_clock::now();
const std::time_t t_c = std::chrono::system_clock::to_time_t(now);
std::cout << "Time: " << std::ctime(&t_c);
std::cout<<"threadID: "<<std::this_thread::get_id()<<std::endl;
for (int j = 0; j < loop; j++) {
glob++;
}
std::cout<<"glob "<<glob<<std::endl;
}
int main(int argc, char *argv[])
{
int loops=10000000;
std::thread t1 (threadFunc, loops);
std::thread t2 (threadFunc, loops);
t1.join();
t2.join();
std::cout<<glob<<endl;
return 0;
}Output
Time: Fri Aug 9 04:02:16 2024
threadID: 140477026113088
glob 10000000
Time: Fri Aug 9 04:02:16 2024
threadID: 140477017720384
glob 20000000
20000000The following program demonstrates that lock_guard only lock the codes within a scope. The programs purposedly enclosed lock_guard in a brace pair, and further run a loop outside the braces. It shows that the threads runs in parallel and cause race data issue.
#include <thread>
#include <iostream>
#include <mutex>
#include <chrono>
using namespace std;
static int glob = 0;
std::mutex mtx;
static void threadFunc(int loop)
{
{
std::lock_guard<std::mutex> lock(mtx);
std::cout<<"***lock critical section"<<std::endl;
const auto now = std::chrono::system_clock::now();
const std::time_t t_c = std::chrono::system_clock::to_time_t(now);
std::cout<<"Time: " << std::ctime(&t_c);
std::cout<<"ThreadID: "<<std::this_thread::get_id()<<std::endl;
for (int j = 0; j < loop; j++) {
glob++;
}
std::cout<<"glob "<<glob<<std::endl;
std::cout<<"***unlock critical section"<<std::endl;
}
std::cout<<"***threads running non-critical section in parallel, race condition occurs"<<std::endl;
for (int j = 0; j < loop; j++) {
glob++;
}
std::cout<<"glob "<<glob<<std::endl;
}
int main(int argc, char *argv[])
{
int loops=10000000;
std::thread t1 (threadFunc, loops);
std::thread t2 (threadFunc, loops);
t1.join();
t2.join();
return 0;
}Output:
The glob value changes wildly in multiple runs\
***lock critical section
Time: Fri Aug 9 04:46:42 2024
ThreadID: 123930279085632
glob 10000000
***unlock critical section
***thread running non-critical section
***lock critical section
Time: Fri Aug 9 04:46:42 2024
ThreadID: 123930270692928
glob 21190478
***unlock critical section
***thread running non-critical section
glob 22084982
glob 31229044Unique_lock
The class unique_lock is a general-purpose mutex ownership wrapper allowing deferred locking, time-constrained attempts at locking, recursive locking, transfer of lock ownership, and use with condition variables.
- When a
unique_lockis constructed with the following constructor, it can take in an associate mutexmtxand immediately starts locking by invokingmtx.lock
std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx);- Alternately, when provided with appropriate optional parameter, the unique_lock can defer locking associated mutex
std::mutex mtx;
std::unique_lock<std::mutex> lk_b(m_b, std::defer_lock);- when unique_lock's destructor is invoked, the associate mutex also unlock.
- alternately, unique_lock can also unlock the mutex using function
unlock().
#include <thread>
#include <iostream>
#include <mutex>
using namespace std;
static int glob = 0;
std::mutex mtx;
static void threadFunc(int loop)
{
std::unique_lock<std::mutex> lock(mtx);
std::cout<<"threadID: "<<std::this_thread::get_id()<<std::endl;
for (int j = 0; j < loop; j++) {
glob++;
}
std::cout<<"glob "<<glob<<std::endl;
lock.unlock(); // can omit because unique_lock destructor is called
// when going out of scope.
}
int main(int argc, char *argv[])
{
int loops=10000000;
std::thread t1 (threadFunc, loops);
std::thread t2 (threadFunc, loops);
t1.join();
t2.join();
return 0;
}